エム・データ、動画コンテンツのシーン内容や文脈、視聴者のモーメントを単語化し分類する「コンテクストメタ」の研究開発を開始
編集部
テレビの放送内容をテキスト化した「TVメタデータ」を提供する株式会社エム・データ(以下、エム・データ)は、動画コンテンツと広告のコンテクスト(シーンの内容や特徴、文脈)やモーメント(視聴者の商品やサービスへの関心が高まる瞬間)を捕捉するための「コンテクストメタ」の整備を開始する。
■背景
コネクテッドテレビ(以下、CTV)の普及と動画配信サービスおよび広告の伸長、またクッキー規制や個人情報保護などにより、個人データは使用せずプライバシーに配慮した「コンテクストマッチ(モーメントマッチ)」という広告手法が注目を集めている。
また、技術の進化により、番組や動画コンテンツの内容や文脈に関連した広告が提供できるようになってきた。
今般、エム・データが生成してきた「TVメタデータ」やその生成ノウハウ、24時間365日のオペレーション体制を活かし、生成AIを組み合わせた、動画コンテンツ(シーンごと)の内容や特徴(映像に映った商材や物体、テロップ、発話内容など)、シーンの文脈、話題などを要素分解して単語化(タグ・キーワード付与)し、その単語に意味や属性を付与した辞書化を行い、それらを共通テーマごとのグループに振り分けるカテゴリ分類を実現する(カテゴリ分類は、例えば、飲食、料理、旅行、美容、ファッション、金融、モビリティ、育児教育、ペット、掃除、ゲームなど)。
加えて、単語やテーマ・トピックの出現状況やトレンド、季節性、コンテンツや番組の特性や傾向、時期ごとの取扱い話題、頻出ワードを分析するダッシュボード構築を進め、時代や世相、意味性の変化、新語の発出に応じて、辞書やカテゴリ分類を定期的に最適な状態に見直すメンテナンス体制を整える。
これらにより、コンテンツのシーン内容ごとの特性やキーワードをタイムスタンプ(コンテンツの時間軸)で捉え、コンテクストマッチ・モーメントマッチ広告を実現するためのメタデータの提供が可能となる。
「コンテクストメタ」は、これまでテレビ局や広告会社、調査会社と共同で基礎的な研究を行ってきたが、今後はパートナー企業との共同テストやPoCによる部分的対応から順次拡張していくことを予定している。
■コンテクストマッチ・モーメントマッチ広告への連携イメージ
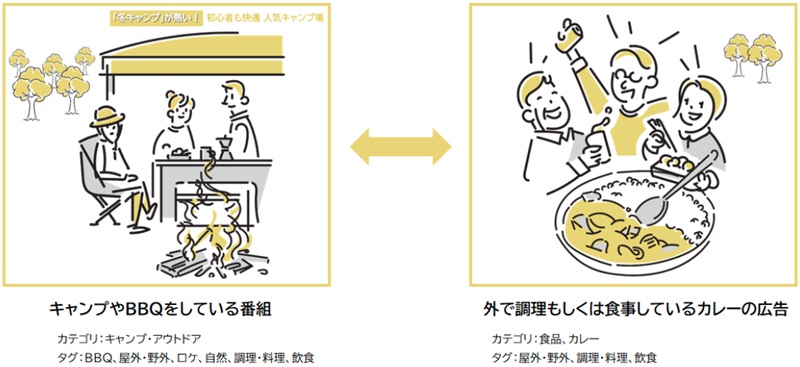
①コンテンツ解析(単語化、辞書化、カテゴリ分類、トレンド解析、定期メンテナンス)したTVメタデータを、②広告解析(広告の商品ブランドの特徴やクリエイティブの内容などを単語化、辞書化、カテゴリ分類)されたデータと組み合わせることにより、例えば、テレビ番組のコンテンツがCTVや動画サービスで配信される際の広告で、コンテンツの内容、文脈にマッチした親和性の高い広告を配信することが可能になる(下図のようにキャンプやBBQ、カレーの食事シーンに、キャンプやBBQの関連商材、カレーの関連商品の広告をマッチング)。
期待効果として、個人データは使用せずに、ユーザーが視聴しているコンテンツ内容やモーメント(商品・サービスへの関心が高まる瞬間)を捉えた関連広告を配信し、商品・サービスとの新たな出会いやマッチングを自然に演出することができる。
動画コンテンツと広告素材の自然かつ違和感のないマッチングを実現し、広告主にはより親和性のあるコンテンツの探索を、メディア側にはコンテンツに最適な広告枠の価値を訴求することが可能となる。
■コンテクストメタの主な要素(一部、構想も含む)
・映像シーンや発話の内容や話題(トピック、テーマ、事柄)、商品、人物、名詞、音楽、字幕・テロップ
・映った物体(オブジェクト)、シーンや背景描写(シチュエーション)
・構成要素や演出要素
・視聴者の印象(エモーション)
・これらのタイムスタンプ(イン・アウトタイム)
※この他、パートナー企業や顧客との協議によりカスタム対応。
※コンテクストメタの充実に加え、カテゴリ分類においても、例えば「料理」カテゴリを、料理のジャンルやメニュー分類などに細分化し、階層化されたマスタ体系も整備し、コンテンツと広告のマッチングの質や精度を高める計画。
※単語・タグ・キーワードなどの辞書や階層化されたカテゴリ分類の充実と、各種外部データと連携が容易になるマスタの整備・統合にも着手する計画。
一方で、これらのマッチングをAIに依存し過ぎると精度や判定ミスが発生し、意図しないコンテンツや文脈、シーンにミスマッチな広告が流れ、ブランド毀損のリスクが伴う(例えば、酔い潰れたシーンに酒類の広告、暴走や事故のシーンに自動車の広告など)。
これらAIによるリスクを軽減し、視聴者の感情や広告主の意図に寄り添ったマッチングを実現するためには、データ生成および①②の運用を人が判断して補正する体制が必要になる。
エム・データは、このようなAIの課題にも柔軟に対応し、TVメタデータの生成と提供をする役割を担う。
今後は、コンテクストマッチ・モーメントマッチ広告の高度化に向け、テレビ局、動画配信事業者、広告会社、調査会社、アドテク会社などとの連携・共創を更に進めると共に、生成AIなどのテクノロジーを駆使し、ローカル局やBS局、動画配信サービスのTVメタデータ生成やコンテンツ解析を拡張するのと並行して、生成AIの課題である精度やハルシネーションの弱点を専門のオペレーターが補正する体制も強化する。
「TVメタデータとAI」を融合させ、既存のTVメタデータを活用したRAGの構築とTV版の「AIエージェント」を確立させ、「放送×動画配信」でのトータルリーチ、コンテンツの再価値化、新たな広告モデルの進化に挑戦、貢献していくという。
■「TVメタデータ」とは?
株式会社エム・データでは、テレビ局で放送されたTV番組やTV-CMを、テキスト化・データベース化して「TVメタデータ」を構築している。データセンターでは常時40名前後の専属スタッフが24時間365日「いつ」「どこで」「何が」「どのように」「何秒間」放送されたかを、オリジナルのデータ収集システムを使用しデータの生成を行っている。
TVメタデータは4種類に区分し、「①番組データ(番組放送内容)」「②CMデータ(広告出稿内容)」「③アイテムデータ(番組で紹介された商品情報)」「④スポットデータ(番組で紹介された店・宿・観光地等の情報)」で構成され、ローデータサービスの他に、ランキングコンテンツや調査・集計・分析等のレポートサービス、分析結果を基にしたコンサルティングサービス等がある。